

자연어이해 프로세스인 JS-언어 분석기는 비정형 데이터 가공을 위해 형태소 분석, 개체명 인식, 구문 분석, 감성 분석 등의 텍스트 분석 기능을 처리하는 기계학습/심층학습 기반의 언어 분석 엔진입니다.
그 뿐만 아니라 자연어처리 결과를 바탕으로 문장에 숨겨진 의도를 이해하거나 질문의 유형을 파악하는 등의 한 단계 높은 수준의 분석 결과를 제공함으로써, 대화처리를 위한 의도 이해 및 분석, 심층질의응답을 위한 질문 의미 이해 등이 가능합니다.
JS-언어 분석기는 AI-service 플랫폼에 포함된 다른 모델들이 동작하기 위해 필요한 기본 프로세스입니다.
솔루션 소개
자연어이해 엔진을 구성하고 있는 고정밀 언어분석기들은 기계학습과 심층학습(인공신경망) 기술이 적용되어 있으며, 대규모 언어자원(분야별 대용량 학습데이터, 사전과 규칙)을 통해 도메인별로 품질을 최적화할 수 있습니다.
현재 구축된 JS-형태소 분석기 2.0은 높은 정확도를 제공하고, 구문 분석과 개체명 추출기는 병렬/분산 처리를 통해 세계 최고 성능을 제공하고 있습니다.
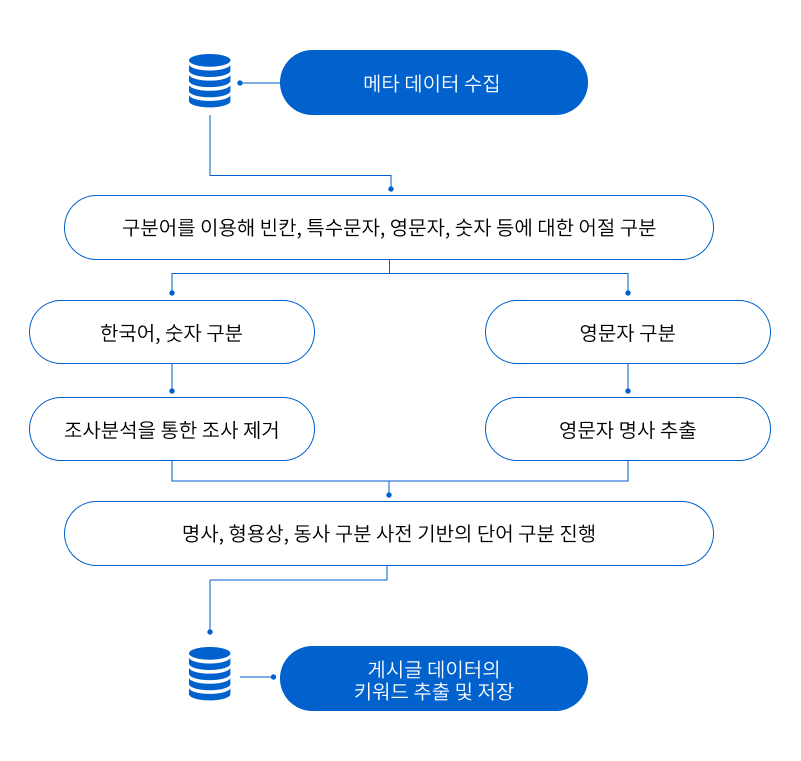
< JS-언어분석기를 이용한 키워드 도출 프로세스 예시 >
기계학습 및 심층학습 기반의 고품질 자연어처리
JS-언어분석기를 구성하고 있는 고정밀 언어분석기들은 기계학습과 심층학습(인공신경망) 기술이 적용되어 있습니다.
최신 기계학습 모델 Structural-SVM에 기반한 형태소 분석 및 개체명 인식, Latent Structural-SVM에 기반한 긍/부정 감성분석, Transition-Based(Arc-Eager) Dependency Parsing 방식의 의존 구문분석은 기존 알고리즘 보다 빠르고 높은 성능을 제공하고, Word Embedding 활용으로 자연어처리에 대한 심층학습 적용을 가능하게 합니다.
도메인 적용의 용이성
일반적인 단어(용어)에 대한 언어처리를 수행하는 보통의 자연어처리 엔진과는 달리, LEA 엔진은 대규모 언어자원을 통해 도메인별로 품질을 최적화할 수 있습니다.
대용량 학습데이터를 별도로 구축하여 학습할 수 있도록 기능을 지원하고, 공통 사전 외에 각 도메인에 특화된 사전과 규칙을 활용함으로써, 의료, 금융, 법률 등 각각의 분야에서 사용되는 언어 특성에 따른 맞춤 분석 결과를 제공합니다.
사전관리 기능
자연어이해 엔진에서 사용되든 주요 언어사전을 통합관리 할 수 있는 사전관리 기능을 제공합니다.
웹 기반의 통합 언어사전 관리 기능을 통해 특정 도메인에 사용되는 중요 용어나 언어처리 시 제외할 단어, 유의어, 동의어 등의 언어자원을 쉽게 추가하고 반영할 수 있습니다.
이를 통해 사용자 또는 도메인에 따른 커스터마이징 된 분석 결과를 제공받을 수 있고, 주기적이고 지속적인 관리를 통해 언어처리 품질을 향상시킬 수 있습니다.