

JS-STT는 음성인식(Speech Recognition)기술을 응용한 딥러닝 기반 모델로서 사람의 음성을 컴퓨터가 이해하여 내용을 문자 데이터로 전환하여 제공하는 것을 말합니다. 학습의 정확도를 위해서는 정확한 데이터를 이용한 기초학습이 주요 요점으로 작용한다. 따라서 자사에서 보유한 98시간의 양질의 데이터로 충분한 서비스가 제공이 가능하며, 전문 분야에서 사용되는 특정단어의 정화도와 인식률을 향상시키기 위해서 데이터의 학습시간을 세분화하여 전문분야 특화된 음성인식 모델을 제공합니다. 또한 음성데이터에서 텍스트로 변화하는 과정에서 문서를 어휘 단위로 나누어 타임라인(Time-Stamp)을 함께 추출하여 고객의 요구 형태로 함께 제공하는 모델입니다.
솔루션 소개
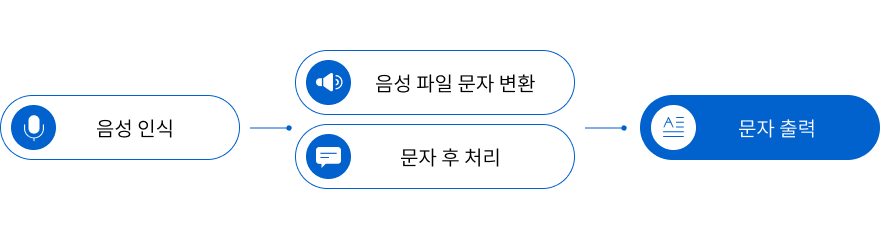
< 음성인식 인터페이스 기반 서비스 개요 >
주요 특성
음성인식 엔진은 딥러닝(Deep Learning)에 의해 고도화된 음향모델 적응 학습을 기반으로 합니다. 일반적으로 사용되는 음성인식 알고리즘인 HMM(Hidden Markov Model) 또는, 기존 Fully connected DNN(Deep Neural Network) 기반 음향모델보다 개선된 음성인식 성능을 보이는 LSTM(Long Short-Term Memory)기술을 적용한 baseline 음향모델을 기반으로 적응 학습 환경을 제공합니다.
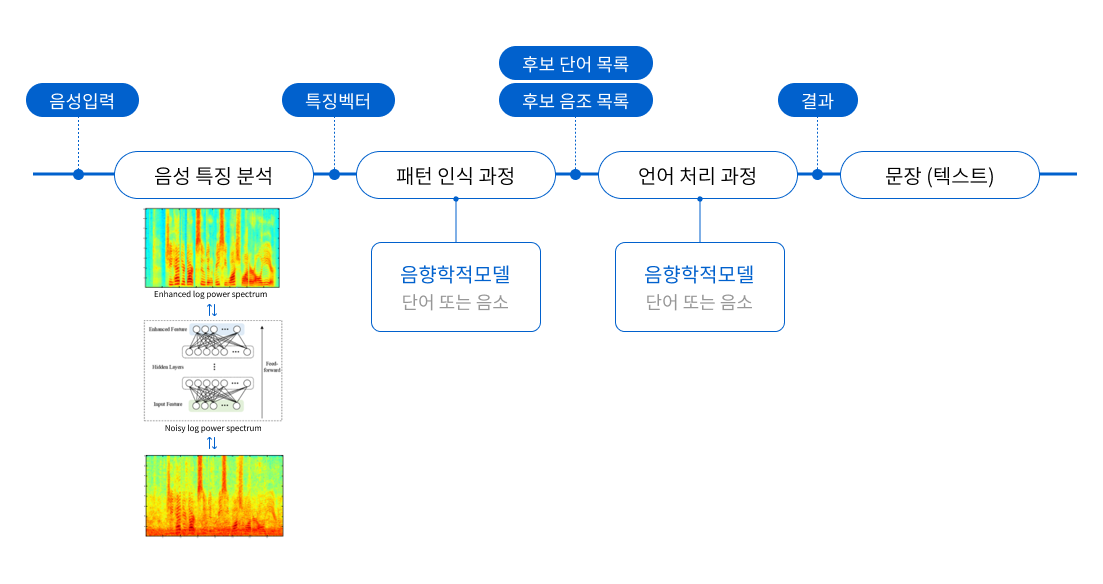
< 음성인식의 심층 신경망 개요 >
음성인식 서비스
음성인식은 일반적으로 음성인식 기능이 필요한 다른 서비스 어플리케이션에서 음성인식 엔진이 제공하는 API를 호출하는 방식으로 사용됩니다. 이를 활용하는 서비스 어플리케이션에서는 시스템 환경에 관계없이 접근하며, 제공되는 기능을 활용하여 다양한 음성인식 기반 인공지능 서비스 구현이 가능합니다.
음향모델 적응 학습
음성인식은 사전에 학습된 모델을 통해 음성데이터를 텍스트 정보로 변환합니다. 이 과정에서 사용되는 학습 모델은 크게 음향모델(Acoustic Model, AM)과 언어모델(Language Model, LM)로 구분할 수 있습니다. 음향모델은 음성데이터에서의 음향적 특성을 통계적으로 모델링하여 학습하게 되는데, 음성인식 프로세스에서 제공하는 기본 모델(baseline model)을 기반으로 실제 적용하고자 하는 음성의 특성을 추가하는 적응 학습이 가능합니다. 특정 분야(콜센터 등)에서 수집된 녹취 음성데이터와 전사 데이터를 학습 데이터로 입력하여 기존 baseline model에 적응 학습을 수행할 수 있습니다. LSTM(Long Short-Term Memory) 기반으로 학습된 음향모델은 HMM, DNN 방식에 비해 높은 음성인식 성능을 제공하고, 해당 분야에 특화된 음성인식 기능을 제공할 수 있습니다.
언어모델 학습
특정 분야(금융, 콜센터 등)에서 사용되는 언어 표현의 특성을 반영하여 해당 서비스에 특화된 음성인식 기능을 제공하고, 보다 개선된 품질을 제공하기 위해 언어모델을 학습할 수 있습니다. 언어모델은 텍스트로 변환되는 문장의 어휘 선택이나 문장 구조 등 문법적 특성을 학습하는 것으로, 대량의 말뭉치를 수집하여 통계적으로 학습하거나, 형식 언어를 통해 임의의 규칙을 정의할 수 있습니다.
고성능 음성인식 모델 제공
음성인식 엔진에서 제공하는 음향모델과 언어모델은 한국어 1000시간 정도의 데이터 학습을 통해 높은 성능을 보장하는 기본 모델(baseline model)을 포함하고 있습니다.