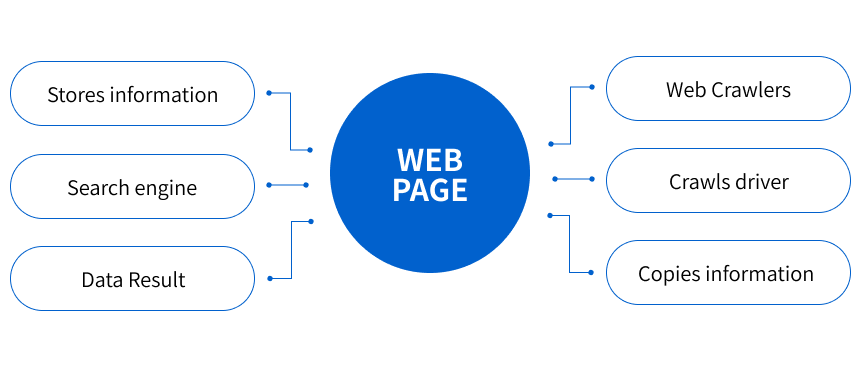
웹 크롤러는 Google, Bing, Yahoo !, DuckDuckGo, Baidu, Yandex 등 많은 검색 엔진이 있습니다. 그들 각각은 스파이더 봇을 사용하여 페이지를 색인합니다.
가장 인기있는 웹 사이트에서 크롤링 프로세스를 시작합니다. 웹 봇의 주요 목적은 각 페이지 내용의 핵심을 전달하는 것입니다. 따라서 웹 스파이더는이 페이지에서 단어를 찾은 후 다음에 쿼리에 대한 정보를 찾을 때 검색 엔진에서 사용할 단어 목록을 작성합니다.
인터넷의 모든 페이지는 하이퍼 링크로 연결되므로 사이트 스파이더는 해당 링크를 찾아 다음 페이지로 이동할 수 있습니다. 웹 봇은 모든 컨텐츠와 연결된 웹 사이트를 찾을 때만 중지됩니다. 그런 다음 기록 된 정보를 서버에검색 색인을 보내 저장합니다.
페이지의 색인이 생성되면 크롤링이 즉시 중지되지 않습니다. 검색 엔진은 웹 스파이더를 주기적으로 사용하여 페이지가 변경되었는지 확인합니다. 변경 사항이 있으면 검색 엔진의 색인이 그에 따라 업데이트됩니다.